To my delight the topic of platforming doesn’t seem to let me go. In that context, I recently looked into what’s going on in container orchestration these days. Again, I should say.
I’ve worked quite a lot with AWS EKS and ECS lately, but it is always interesting to see what’s new out there, or just see what other people are doing. As an engineer, you always run at risk to dive too deep into a specific tooling or vendor - or both. Well, it’s not really a risk. You know: it’s a specialization. And quite fun. It certainly pays well. While Kubernetes tickled me to go down that road again - as I did with other toolings in the past - I am more interested in a different thing, in which container orchestration plays a role, but not the only one.
That different thing I can best describe as an application platform, in lack of a better naming. This term is already in use in multiple contexts. In this article I do have something specific in mind. So for the scope of this article, an application platform consists of:
- An application runtime, that is an environment in which applications, that may be addressable, can be started in
- An ecosystem of components, access to one I mean; whatever the applications require, like databases or data lakes or whatnot, so they can do what they do
- An interface to instrument all the above, that means lifecycle management of applications and code deployment of application versions and that can be used by 3rd parties
As one image tells more than a thousand words, here is a diagram. That must help even more. You decide:
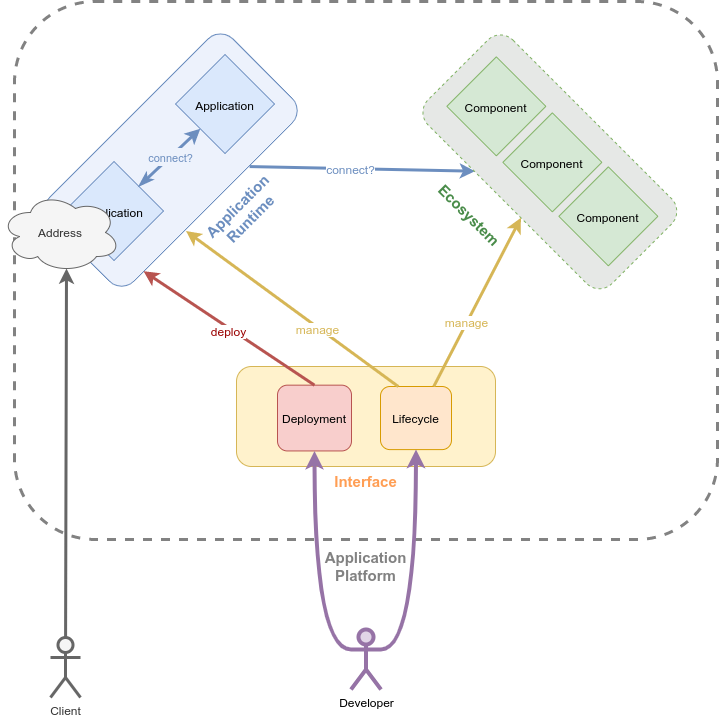
An Old Friend
This pattern is not new at all. I think it keeps following me around. Or am I chasing it? Either way. The first time I engaged with it was at the beginning of my career in tech. I was working in web hosting, mail hosting and related services.
Looking back at that time, the early 2000s, I can’t help but seeing the same pattern. Sure, nobody was speaking about application platforms back when. Certainly not me. It was plain web hosting, marketed under poetic names like “Web XXL: 123 domains, 10 GB Storage, PHP and MySQL - only $1.99”. Fun times. Either way, the shoe fits:
- a (specialized) runtime (here: PHP, before that CGI, later other scripting languages)
- the right ecosystem (MySQL and so forth)
- an interface - well multiple - for deployment (FTP 😳) and lifecycle management (some website in essence)
I would call that a specialized application platform nowadays.
In the 2010s the IaaS vs PaaS vs SaaS framing became a thing. PaaS is another implementation of the application platform pattern. Compared to earlier approaches, PaaS increased the range of offered runtime specializations vastly. They rethought usability, with new developer focused CLI based lifecycle management and deployment tooling. And of course: everything now had an API. Either way, still the same pattern.
Towards the end of the last decade, I left public hosting - by then called public PaaS - and entered private company country. What I didn’t leave, what stuck around was the pattern of course. Again there are developers, which need to run their applications. Resulting from that, an ecosystem providing peripherals for those applications is required. And of course some kind of interface to deploy code and manage lifecycle must be available as well. From what I can tell, every tech company out their has their variant of that. Assuming they have enough application developers around to merit any kind of standardization. There must be thousands of variants and implementations.
An Experiment
Ok, so where does Infrastructure as Code (IaC) comes in then? Well, it’s a topic that I am deeply engaged with currently. As I am with application platforms. So here we are. I also have a hunch, this could mean less time with enormous YAML files in the future. So it’s worth looking deeper into!
It makes great sense from where I am standing. That is: environments, in which many developers collaborate and work with (cloud) infrastructure directly. So everybody is using IaC already, meaning introducing external things (like an open source PaaS or such, that “leave the IaC ecosystem”) is not ideal. Having an application platform managed from the same code that also defines all (the other) resources seems a good idea. If just to have one less context switch.
I also figure that there is a minor paradigm shift ahead. Right now, IaC is used to provision and manage (cloud) infrastructure resources. Those are mostly primitive resources. I mean things like a virtual machine of certain proportions, tcp load balancers, a DNS zone with records. The kind of stuff APIs of the infrastructure provider have in stock (1, 2). In the future, I imagine, IaC will be mainly used to provision and manage high level patterns. Or maybe not mainly, but also. Either way, how that could look like with whole application platforms, is my question.
Before getting into the details here some assumptions I am making - based on my own situation, but also from what I am reading and seeing others do:
- Resources can be managed via IaC: This experiment is limited to (cloud) infrastructures, that provide APIs for which an IaC implementation is available.
- IaC is best practice: Describing infrastructure in code is the (current) best way to run and maintain infrastructure.
- People are familiar with IaC: Many engineers in the field are already knowledgeable with IaC. Both the general concept and specific implementations. This came as a byproduct / consequence of DevOps et al.
To boil down the the idea under investigation into a single sentence:
Can a useful, production grade application platform be build using only Infrastructure as Code?
IaC ≠ IaC
To clarify what I mean, I need to elaborate a bit on the state of IaC, as I see it. If you follow my blog you might have read my recent article in which I dove deeper into what’s going on with IaC lately. In short my findings: Where IaC used to be writing ginormous YAML files (or akin), it progressed to writing actually unit-testable code in a high level languages like Typescript, Python, etc - with all that comes with that in terms of modularization, actual control statements, arbitrary code execution and so forth.
So when I am speaking about IaC in this article, I am referring to this latest iteration. Like AWS CDK or Pulumi or - coming soon - Terraform CDK. Basically any IaC framework, that provides the following properties:
- Constructs, that is infrastructure resources as complex types (=construct) in the respective higher level language
- Composition of constructs from other constructs
- Modularization of re-usable code
Kinds of Constructs
One more tidbit, that helps in discussion and framing of thought is to agree on names for the different “kinds” of constructs there are. Amazon came up with a grouping / naming scheme, that I’d like to rephrase a bit to make it independent of a (their) specific implementation:
- Level 1 Constructs (L1): Low level infrastructure constructs, which have the interface that is defined by the infrastructure provider. To use them you must be deeply familiar with the resources offered by a particular infrastructure (provider). It exposes all possible functionality at the price of high complexity - and often awkwardness, given that this interface was not designed for immediate high level programming language usage.
- Example: (S3)
CfnBucketmatching the S3 Bucket CloudFormation YAML.
- Example: (S3)
- Level 2 Constructs (L2): Higher level infrastructure constructs, that have a convenient interface, easy to use in higher level language with the least amount of boilerplate, good sensible defaults and easy to combine with other infrastructure constructs. L2 is kind of an “adapter layer”, hiding away the grizzly L1, which was not designed for usage in higher level languages.
- Example 1: (S3)
Bucket, in a higher level than before. - Example 2:
DockerImageAssetthat represents a Docker (container) image.
- Example 1: (S3)
- Level 3 Constructs (L3): Logical infrastructure constructs, that are composed of L2 (or L1 or both or other L3 etc) infrastructure constructs to implement complex patterns. That can be as easy as wrapping two L1/2 constructs together or any complicated pattern composed of any number of things:
- Example 1: Simple Lambda with an S3 bucket together)
- Example 2: Complex static website hosting consisting of CloudFront, S3 and Route53 constructs
At the risk of repeating myself: While I was using only AWS CDK in the examples above, the L1-3 grouping is by no means only applicable to this framework. Any IaC framework that provides L1 and/or L2 constructs and allows you to (easily!) construct L3 constructs from them suffices:
- Terraform CDK allows you do use any existing “regular” Terraform provider, or rather compile the HCL definitions of those providers into constructs in your respective language (say Typescript). If you have a look at some usage examples you might agree they look like L1 constructs (that is: they have a powerful, but awkward, low-level interface). This of course means L3 could be constructed from them with ease.
- Pulumi’s constructs I’d probably consider more L2 than L1, but then again. Look at their API and judge for yourself
Preparation
Before going into any implementation, let’s check against the requirements from the top. That should elaborate on what is missing, what needs to be implemented so that an application platform in pure AWS CDK can be created.
Requirement: An Application Runtime
For an application runtime, we need to define what an application is. Again, a general purpose runtime that runs truly everything is out of the question. Let’s keep it simple - but not too far from the real world - this is an experiment after all.
Application: I started this article with container orchestration and I think that is a good starting point here as well. Let’s say an application is encapsulated in a container. Docker, to make it specific. That comes with a few standard concerns when using containers: exposed port, environment variables, resource sizing, etc. Also, as that is simply standard by now, there should be some resource based auto-scaling available. That is already not bad. If an application is supposed to be everything (within reason) that we can box into a container and that can have an exposed network port, then about every HTTP service would already “work”. Let’s go with that.
Runtime: The container based definition makes it also quite easy regarding the runtime. AWS offers two kind of container orchestrations: EKS (managed Kubernetes) and ECS (managed, proprietary container orchestrator). Both would do for an experiment. Sure, I could run Nomad or something on EC2 instances, tho I gonna stick with the managed services.
Requirement: An Ecosystem of Components
We already got that, luckily. When using AWS CDK, we can use all the resources AWS provides, as long as the implementation of the previous Application and Runtime definitions do not interfere with that. In short: As long as I don’t screw it up, we have a huge ecosystem available.
Requirement: An Interface
That is also already in place. AWS CDK itself is that interface, both for deployment and for lifecycle management.
Lifecycle management: That is kind of obvious I guess. As the AWS resources are defined from AWS CDK that also manages their lifecycle. Done.
Deployment: As we agreed that basically anything dockerized is an application, the DockerImageAsset from the aws_ecr_assets library can be easily used to reference a local Dockerfile and then build and upload that during deployment. Good enough for my experiment.
Drafting an Outline
Ok, with the outcome from the above, we’re left with needing that Runtime and Application available as (L3) constructs in AWS CDK. With that goal, I like to start with a quick draft of (pseudo-)Typescript code, to outline what needs to be created. I’ll try to keep the Typescript and AWS CDK boilerplate low, sometimes only hint to it, to make it readable for anyone. The most interesting part will be the interfaces, that is the configuration properties of the constructs. These describe functionality the L3 implementations will need to provide.
First in plain English. What am I expecting to end up with when running cdk deploy? Something in between a user story and acceptance criteria, if you will:
- A compute environment, that can run docker images, is created (e.g. container orchestrator) -> Application Runtime
- A container image is created from a defined directory
/path/tothat contains aDockerfile-> Interface (Deployment) - A service runs, that uses the uploaded docker image, with all requested resources (cpu, memory) -> Interface (Lifecycle)
- The running service is addressable (
https://my-app.public.domain/) -> Application Runtime - A SQL database is running, that the service can use -> Ecosystem
This is very superficial of course. That makes the sample code also shorter and better to understand. I hope:
// here would be import of all the things, then:
class Stack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// create the runtime, within which the application will run
const runtime = new Runtime(this, 'RuntimeCluster', {
// make the suffix, the namespace the same for all things running inside
domain: 'public.domain',
// + AWS specific options, like VPC? Availability Zones? Timeouts? etc
});
// create the actual application
const application = new Application(this, 'RuntimeApplication', {
// reference the runtime to run in - application and clusters should
// also be creatable in independent stacks, even entirely independent
// CDK apps... problem for later
runtime: runtime,
// so we can speak about it
// Someone: the hamster is down!
// Someone Else: oh no, not the hamster!
// true story
name: 'my-app',
// that path in which that Dockerfile is
code: '/path/to',
// the resources - unsure yet what the ideal structure would be
resources: 'cpu 1, memory: 512',
});
// this is very pseudo - look here for an actual AWS CDK example:
// https://docs.aws.amazon.com/cdk/api/latest/docs/aws-rds-readme.html
const database = new Database(this, 'Database', {
// dummy properities, showcasing a SQL database being provisioned
engine: 'mysql',
resources: 'cpu: 1, memory: 1024, storage: 10',
});
// the application should be able to access things in the ecosystem
database.grantAccess(application);
}
}
That looks usable, as in: Not too much boilerplate, I can imagine maintaining that. So I believe for now the interfaces are sensible enough. I guess they contain all the information that is required to satisfy the above acceptance criteria.
There are a couple of things that come to mind:
- Use as an Application Platform: To make that happen, I would likely deploy the Runtime once or more (stages?) per AWS account, then everyone with access to that account can deploy Applications there. So there must be an easy way to reference a deployed Runtime from the Stack that defines the Application.
- Cost: There are a couple of ways to shape the costs. Like dedicated load balancer per application vs shared and such. NATting can also increase cost. Thinking of cheap development environments vs reliable production. Lots of room for tuning configuration.
- Access management: As showcased in the bottom of the draft, there needs to be a “natural” way to integrate with the ecosystem. Also in between services.
- Scaling conditions: These services should be able to scale, based on load. The conditions in which that happens should be describable in the interface.
- Persistent vs Scheduled Executions: To simplify, there will be things that run all the time, like web service, and things that are scheduled at some times, like reporting or such. Both should work. Maybe split Application into two related constructs?
I am sure you can think of more, and so will I in the implementation.
Prototype
So I wrote something: https://github.com/ukautz/aws-cdk-app-runtime
It’s not the minimalistic Proof-of-Concept (PoC) I imagined initially. Since I am doing this in my own time, I often end up in such excursions looking into multiple topics that interest me. In this case, among other things: Traefik. I wanted to put that to use for a while and see how it runs. Now I did and therefore the traffic routing of my PoC became more opinionated. Ok, before jumping too much into details, let me show you some code and then elaborate a bit on how I can imagine it can be used.
Show me the code
To compare against the above draft outline, here the respective actual code that implements the user story:
import * as cdk from '@aws-cdk/core';
import { DatabaseInstance, DatabaseInstanceEngine, MysqlEngineVersion } from '@aws-cdk/aws-rds';
import { Port } from '@aws-cdk/aws-ec2';
import { Cluster, Service, Resources } from '@ukautz/aws-cdk-app-runtime';
import * as path from 'path';
export class MinimalStack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const publicDomain = this.node.tryGetContext('publicDomain');
if (!publicDomain) {
throw new Error('missing publicDomain in context');
}
const cluster = new Cluster(this, 'Cluster', {
publicDomain,
privateDomain: this.node.tryGetContext('privateDomain') ?? 'service.local',
});
const service = new Service(this, 'WebApp', {
cluster,
image: 'path:' + path.join(__dirname, '..'),
name: 'my-app',
public: true,
resources: Resources.fromString('cpu: 256, memory: 512, min: 2, max: 10, target_cpu: 50'),
});
const database = new DatabaseInstance(this, 'Database', {
engine: DatabaseInstanceEngine.mysql({
version: MysqlEngineVersion.VER_8_0_23,
}),
vpc: cluster.vpc,
});
database.connections.allowFrom(service, Port.tcp(3306));
}
}
I think that doesn’t look too different from the outline. Especially in terms of simplicity (aside from that database cough), it seems to be not to cumbersome.
The resource and scaling claims cpu: 256, memory: 512, min: 2, max: 10, target_cpu: 50 from the draft I liked and came back to it. It reads like this: 256 CPU shares (with 1024 being “one full CPU”), 512 MiB of memory, run at least 2 and at most 10 instances. Scale based on CPU consumption, keep it around 50%.
There is internal form, shaped by complex types, that would look like this:
{
cpu: 256,
memory: 512,
scaling: {
mode: 'scaling',
minCapacity: 2,
maxCapacity: 10,
thresholds: [{ resource: 'cpu', target: 50 }],
},
}
The string form can be easily provided as a --context parameter to execution, so I mostly use that, especially when test deploying services from the command line. Check the tests for examples.
If you want to see more code, there is an example in the library, which implements a simplistic uptime / status tooling for HTTP URLs. It consists of one scheduled service, that queries the URLs and persists metrics in a DynamoDB database, showing of how to integrate with other AWS constructs. This database is then queried by a web application, that can render those metrics in graphs or provide them via a REST JSON API. To show off public / private access, this web app is not accessible from the outside, but made available by yet another service: a proxy app.
Big Picture
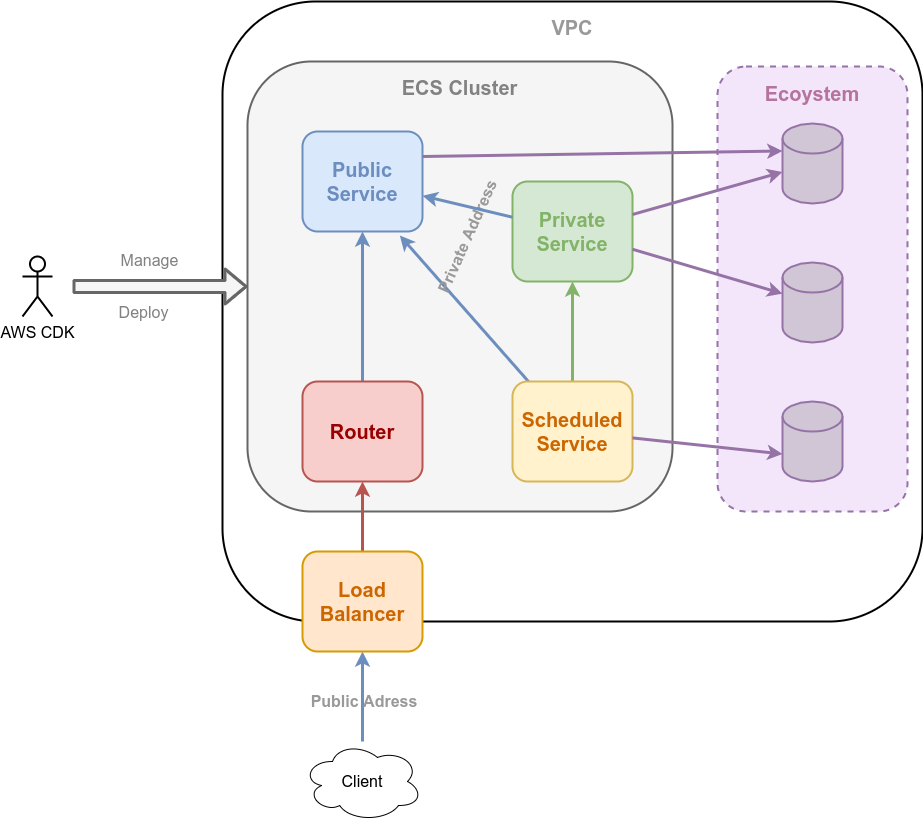
A rough picture of the implementation.
The core of the Runtime, the Cluster, is implemented using AWS ECS (Fargate). So there run the docker images that are stored in ECR during deploying with AWS CDK.
There is no good reason why I didn’t go with with EKS. Might do that next. Also using managed EKS or even running any custom orchestrator on EC2 instances should be doable. I might have tried AppRunner, but that is still only Level 1 at the time of writing. We’ll see.
Services are continuously running applications. They can be addressed under a shared public domain https://some-service.public.domain/ and/or, only from within the VPC, via a shared private domain http://some-service.private.domain/. The public domain is routed to an ALB (*.public.domain), which routes all requests to a service that runs Traefik, which routes the traffic to instances of the named service. Internal routing is done via Cloud Map (service discovery in AWS orchestration). Provided resources, CPU and memory, can be set. Services can run in fixed amounts or scale based on resource consumption.
Scheduled Tasks are applications that are executed at specified intervals (crontab, rate). They can access Services, but not vice versa. Runs only as long as execution lasts. Provided resources, CPU and memory, can be set. Concurrency for execution can be configured.
Everybody can access things in the AWS ecosystem.
Real world applicable?
Yes, I think the approach is sound in principle and integrates nicely with the ecosystem. Not necessarily my experimental implementation, mind you. Since I used my private AWS account, I tried to keep costs low - aside from rare times of simple load testing. So I made decisions, which complicated things, but allowed me to run everything cheaper.
However, if you are using IaC already strongly, I think this approach should be of real interest to you. As with everything, there are advantages and disadvantages. Read on and decide for yourself.
Use as Application Platform
This interests me most, of course. In short: When using AWS CDK anyway, this approach seems a good idea. Modularization of higher level patterns into (Level 3) constructs, that standardize & simplify re-use, I mean. Even embedding (if only minimal configured) custom services - like I did with Traefik here - seems not to hard. Integration with other resources from the ecosystem (AWS) is nicely solved, e.g. through interfaces like IConnectable or IGrantable.
One requirement in that context is to account for separate maintainers / owners of the runtime (the cluster with routing and all) and the installed services (the business applications). Context is of course to provide standardized infrastructure, a platform, to a lot of developers, which share requirements (company, same market, programming framework, many things). It seems that can be solved, if tho it feels a bit hack. See below for how I did that.
I also don’t see conflict with using it in a multi tenant / team situation. There could be one or multiple concurrent Cluster installed per AWS account, or across accounts. It depends then more on the connection of the networking, how the VPCs are setup, peered, routed, filtered etc. Security groups can be used additionally. No conflict with multi region either.
A negative experience was the deployment to ECS Fargate. Same as with “regular” ECS, to my experience. It is annoyingly slow, especially for the high frequent deployments I did, when tinkering with my proof of concept. Although, I understand that’s done for availability and rollbacks’ sake, it still wasn’t enjoyable to wait so long.
There are of course also limits of this approach. The interfaces of the constructs must be sufficiently simple to be useful and maintainable. That constraints the possible applications and can / will make implementations opinionated for specific use-cases. I have a gazillion Kubernetes manifests in mind here..
Regarding the separation of runtime and applications
I went with SSM parameters as the transport / storage. It then works like that:
- Cluster Stack, maintained by platformers, deploys the runtime and stashes all relevant information of the deployed Cluster (the “cluster specs”) in SSM with a well known prefix (
/<prefix>/<parameter..>) - Application Stack(s), maintained by developers, reads the stored parameters from SSM and has all the information required to deploy their applications into the runtime.
This satisfies the requirements for the moment. The “Systems Manager Parameter Store” seems a good choice, just going by the name ;) Whether it actually is, I guess time will tell.
I did not consider access constraints for those SSM parameters for the moment - but that could be done via IAM of course.
Either way, here is how you use it:
CDK application deploying the cluster
import * as cdk from '@aws-cdk/core';
import { Cluster, ClusterSpecs } from '@ukautz/aws-cdk-app-runtime';
// define stack
class ClusterStack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// create the cluster in this stack
const cluster = new Cluster(this, 'Cluster', {
publicDomain: 'public.domain',
privateDomain: 'private.domain',
});
// write the specs (properties) of the cluster to SSM
ClusterSpecs.toSsm(this, '/namespace/', cluster.specs);
}
}
// create stack
const app = new cdk.App();
new ClusterStack(app, 'Cluster', {
env: {
account: process.env.CDK_DEFAULT_ACCOUNT,
region: process.env.CDK_DEFAULT_REGION,
},
});
CDK application deploying a set of services and scheduled tasks in the cluster
import * as cdk from '@aws-cdk/core';
import { Service, ClusterSpecs} from '@ukautz/aws-cdk-app-runtime';
// define stack
class ApplicationsStack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// load from cluster stored specs from SSM
const clusterSpecs = ClusterSpecs.fromSsm(this, '/namespace/');
// create some services in existing cluster
new Service(this, 'Foo', {
cluster: clusterSpecs,
image: 'path:' + path.join(__dirname, '..', 'foo'),
name: 'foo',
public: true,
});
// create some other services in existing cluster
new Service(this, 'Bar', {
cluster: clusterSpecs,
image: 'path:' + path.join(__dirname, '..', 'foo'),
name: 'foo',
public: true,
});
}
}
// create stack
const app = new cdk.App();
new ApplicationsStack(app, 'Cluster', {
env: {
account: process.env.CDK_DEFAULT_ACCOUNT, // << for ssm, reading from which
region: process.env.CDK_DEFAULT_REGION, // << account & where?
},
});
Routing
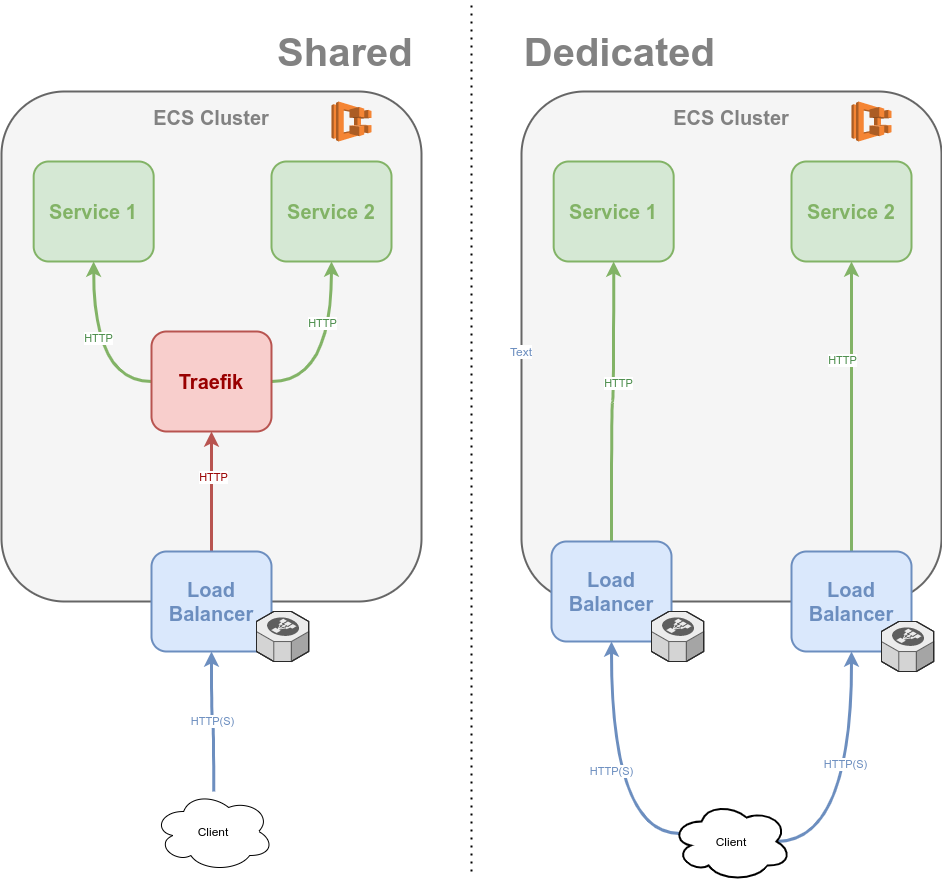
There are many approaches to expose the running services. In AWS you usually use a load balancer (ALB, ELB, ..) to expose services, that run on multiple instances (ere: in ECS). One initial decision was whether to dedicate such load balancer resources per service or use a shared routing layer. The shared could be a SPOF, bottleneck, etc and adds latency. I still went with it. For $$ reasons, but also Traefik.
All public services are then addressable by their public service address name.public.domain. Internally, that means:
*.public.domainis routed via Route53 to an ALB- The ALB routes all traffic to an ECS Service running Traefik
- Traefik routes - based on the prefix (
name) of the public domain (name.public.domain) - to ECS tasks (i.e. the running container instances of the service)
One nugget: The Cluster has a parameter for a secret request header + value. Intended use case: behind CloudFront.
For private traffic routing, when addresses like http://name.private.domain/ are accessed from within the VPC, the implementation looks different. I wanted to see how Cloud Map works for service discovery. It works. Instead of an ALB (which could / should? be used in between) the address name resolution returns in turn each IP (random aka WEIGHTED) of the instances (tasks) of the service. Unsure if that will work like a round robin(‘ish) - or not. Experimental, is my excuse.
Related to this is the outgoing traffic. Per default, all egress is permitted (could be modified, I didn’t have that use-case). The standard / best-practices in AWS here is to use NAT gateways. This is done per default in my implementation, but can be modified to use NAT instances instead. That can make the whole setup way cheaper, but also adds SPOFs! See a comparison here.
Outro
That was fun. Anyway, this is just a PoC, an experiment for now. I would be exited to do the same with Terraform CDK. Once it’s stable enough. Also Application Runtime as Code is just one pattern expressed in (L3) constructs. There are others. Would a higher level framework make sense? Well, it would be certainly very interesting to look into.


