In my previous article I wrote about the benefits of platforms and how platform engineering and DevOps fit together. In that context I thought about end-to-end responsibility. The thing is: it doesn’t work at scale. It just gets way too complicated! Well, that is not the whole truth. You can make it work, even in the largest of structures. Here is how:
What is End-to-End Responsibility?
Ok, let’s pause for a moment. Get a coffee or a tea (or whatever beverage you prefer) and settle in for I am going to tell a story.
The story is about two amazing teams. One team is great at developing software. They take the most intricate and complicated requirement and solve them by creating easy to understand and beautiful to behold applications. What they produce is free of annoying bugs and unexpected behaviors. They pride themselves in testing and benchmarking all functionality rigorously.
The other team is brilliant in operating all kinds of software. They know the underlying operating systems and infrastructure services by heart. They have seen hundreds if not thousands of custom applications and have years and years of experience running about everything you can imagine in production.
Both teams should work splendidly together, no? One writes a marvelous application, the other operates it flawlessly. Everyone is happy ever after. Right? Wrong!
What actually happens, and this is a true story, is this: the synthetic load that was used to test and benchmark the application fails to match actual production characteristics, hence the life performance of the application is abysmal. It also has a host of external network dependencies that make it behave erratic as the external service uptime and responsiveness are highly volatile. The application further suffers from memory overflows that result in out-of-memory kills and the garbage collection leads to random freezes. None of which was visible during development or testing, as they only occur in high load situations after sufficient time.
Worse: The operations team fails to provide actionable details about the issues to the developers. Their extensive metrics that measure their infrastructure add only confusion and noise, but do not help to narrow down on the root causes of the application issue. It takes operations hours to roll out new versions and it’s rarely clear from which release the logs that are provided to the developers are generated from. The staging and production environments differ from each other, so that code changes that work in one fail in another.
In short: it is a huge mess. This is not a happy place.
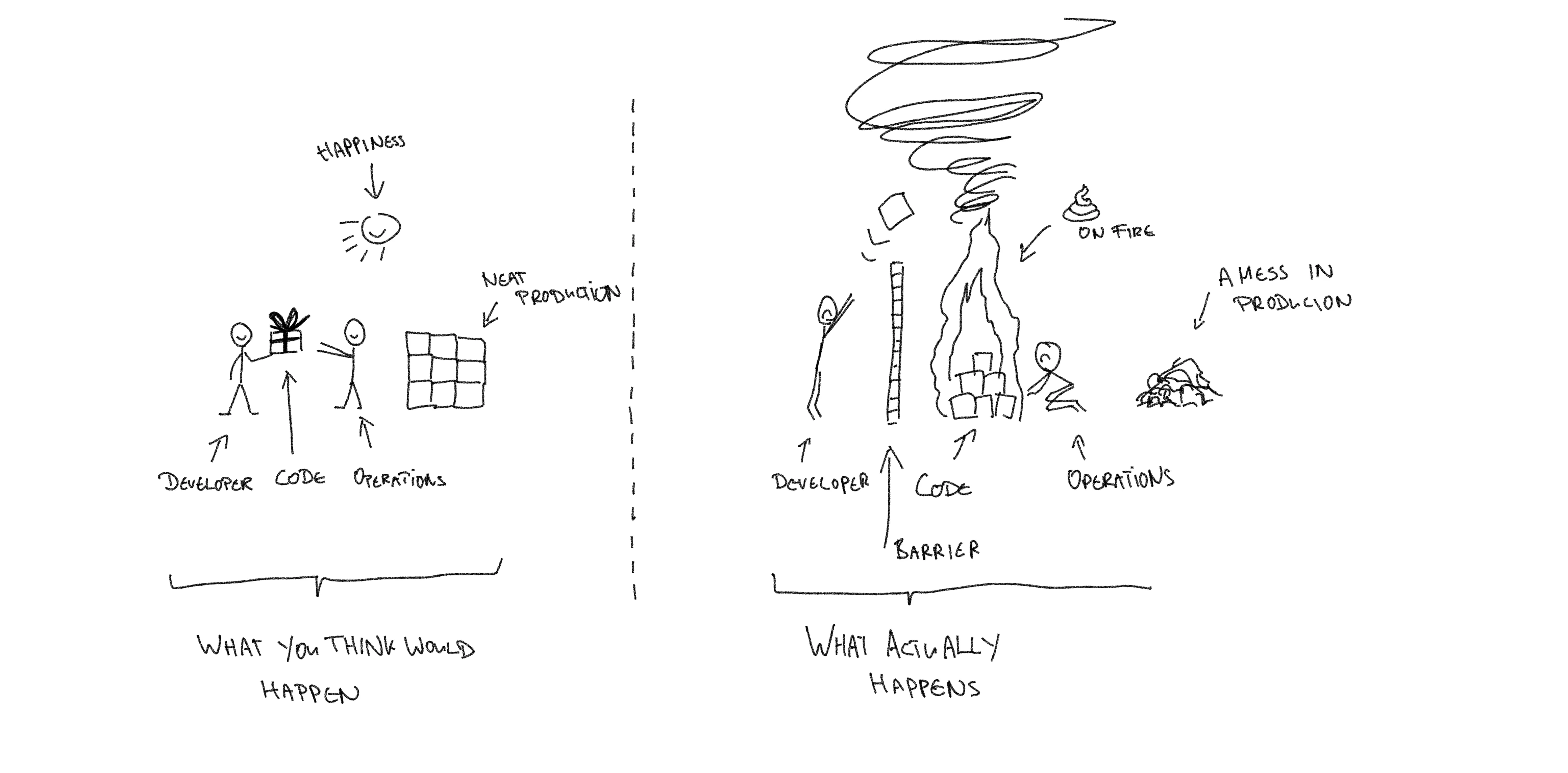
To put a name to the problem that arises: silofication. Knowledge is constrained to the borders of specific departments. Processes end at those very boundaries and do not interconnect. Basically: communication pathways are broken down. As a result traversing those boundaries (like handing over code from development to operations) suffers from a huge bottleneck at best and raging storm of excrement at worst.
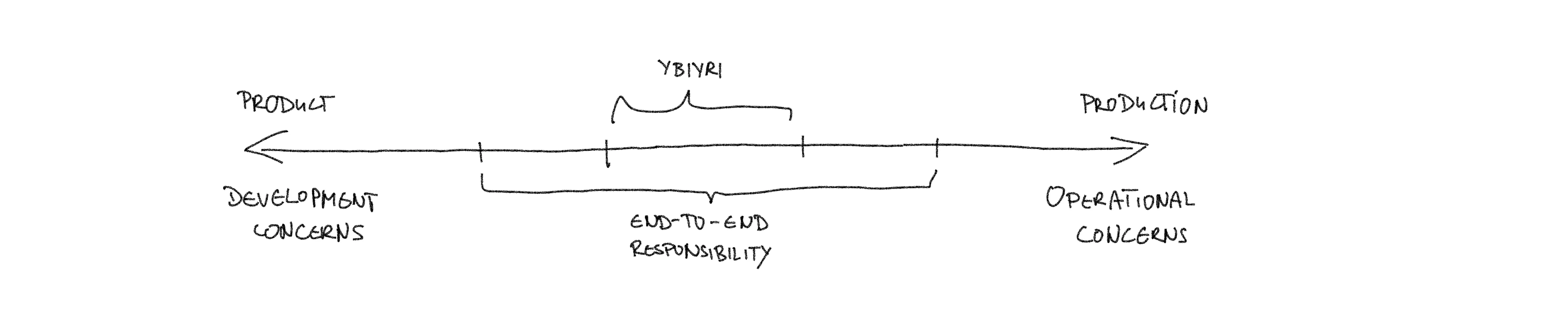
It is 2006. Enter Werner Vogel, freshly minted CTO of an ambitious internet bookseller named Amazon. He utters one phrase that shakes up a whole industry and that still echoes nearly twenty years later: You build it, you run it (YBIYRI). As insignificant as that may sound, YBIYRI shaped modern tech organizations as deeply as the advent of cloud computing. The meaning of YBIYRI is pretty straightforward: as the team that builds a piece of software you are also responsible for operating and maintaining it. That’s it. However, as simple as that idea is, as large are the consequences. The responsibility of running your own application causes a significant shift in perspective: reliability, security, scalability – all of these things have immediately different priorities assigned, because they directly affect you as the developer that created the code. Not only that: as the author of the application, you have deep insight into any possible arising issues as anyone else could have. Communication pathways are not only re-established but also shortened to zero length, because the people that dig into the code and dig into the operating system log files are the very same!
There is just one little problem: you have a team of excellent software developers that have little experience with operating anything in production. What do you do? Easily: merge the operations team and the software developer team. Have one team that has all the knowledge required to both develop and run the software. Have them both share knowledge and grow together into a new team that operates under a new paradigm. And with a last Puff the earlier mentioned silos are gone. YBYRI. You may also have an inkling what those teams that were staffed by developers and operational engineers were called later on – but this is another story. For now let’s just call such teams owners, as in: teams that own products and that are responsible for them. These owners are very interested in making the deployment of their software very easy. They want to have sensible insight into their application behavior at runtime. They want to be able to roll back changes fast and with ease. The good news is, they can do all of that by being staffed with engineers that focus on operations. Sure, in reality it took a bit more than just merging teams. There is a whole organizational mindset that had to be shifted and I believe the model truly gained significant adoption only after programmable infrastructures became more widespread.
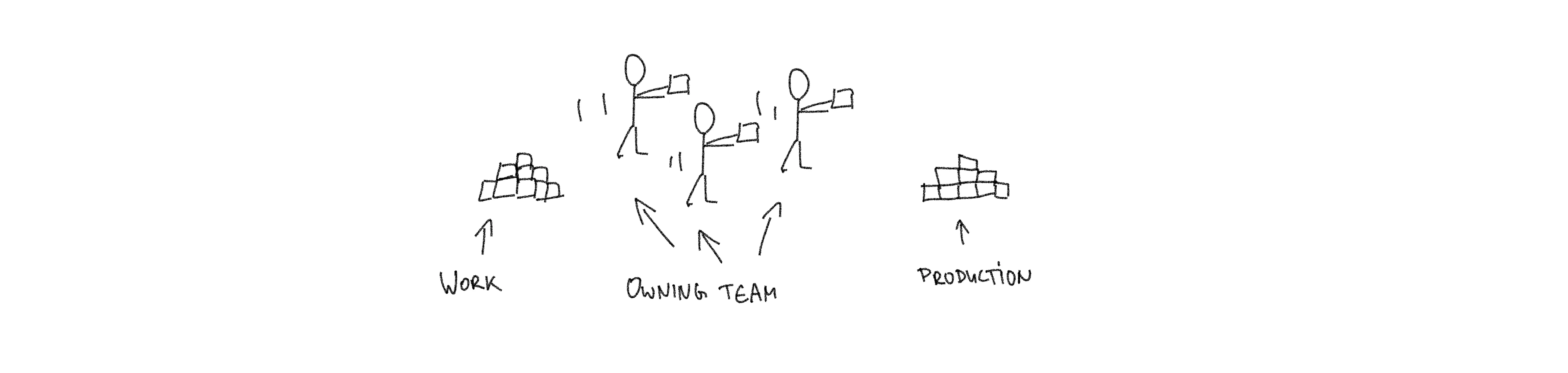
So what is end-to-end responsibility then? I think you could call it YBYRI+ or something like that. While YBYRI proposes development and running of the software is done by the same people under end-to-end responsibility teams go farther in “both” directions: what happens before development and what happens after the software runs in production. On the development side in addition to building the software end-to-end responsibility also requires the team to gather all requirements and then design / architect both the software and the infrastructure. On the other “end” owners also take care of support and gather user feedback. So YBIYRI is a subset of end-to-end responsibility. However, your mileage may vary and I have seen YBIYRI setups that were indistinguishable from what I described here. I have no doubt there are end-to-end responsibility implementations that are more limited (and implementations that are more extensive) than what I describe.
In a now very old podcast with Martin Fowler and Jez Humble I heard a sentence that stuck with me: the job of developers is to take business ideas and turn them into measurable business outcomes. To me, a team that starts with such a business idea and makes it happen truly implements end-to-end responsibility.
Why does End-to-End Responsibility fail at Scale?
When you apply the above strategy of creating owner teams that are skilled in developing, running and maintaining the software, then everything will work splendidly – at the start. However, if you are growing, you will eventually run into a wall. That wall manifests itself by massively slowed down development, reliability problems in production, very short retention of employees – and a whole host of other problems that are all bad. Some of these problems may even look very familiar to you, like those you had before you switched to the end-to-end responsibility model.
Why is that?
First I need to clarify one thing: what does at scale mean? I think it is intuitively clear that at scale refers to large systems as opposed to small systems. However, what makes one system large compared to another? Amount of people working on it? Kilowatt hours consumed? Compute resources available? Sure, all of that, to some extent. However, what it comes down to is ultimately one thing: a large system is more complex than a small system. At scale it is complexity that becomes a problem for end-to-end responsibility.
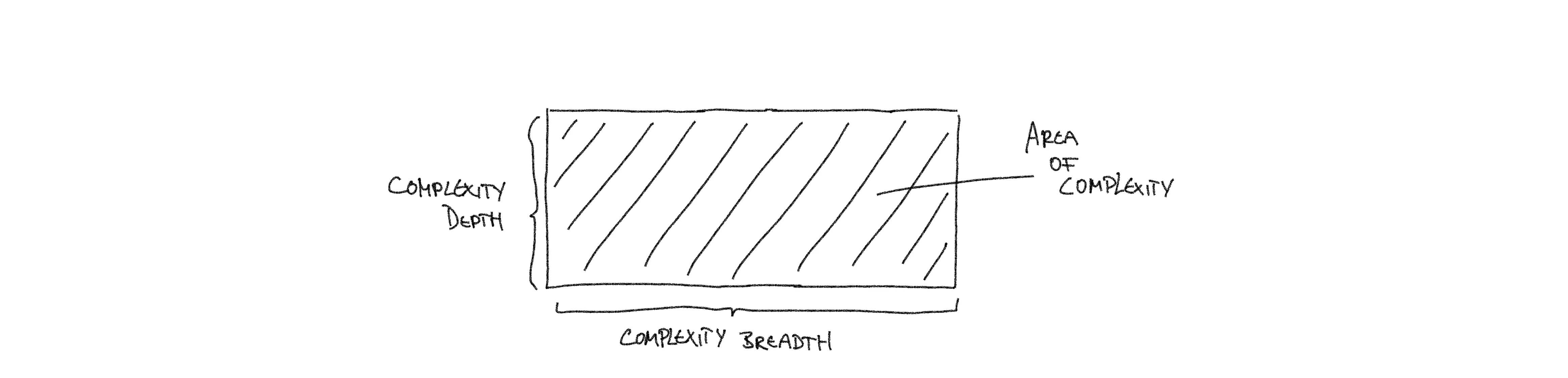
Think of complexity in two dimensions:
- Depth, as in: a single application becomes more complicated through adding functionality. More functionality means more components and more interconnections between components. More knots and bolts = more complex.
- Breadth, as in: a large quantity of simple, but different applications form a complicated tech stack. Adding more applications that have different architectures, that use different components or use components differently all adds more complexity to whole. Relationships in between applications add further complexity proportional to the amount.
You can also think of Depth as the Team-Level perspective: the complexity each member of the team has to engage with when working on their application / service. Likewise Breadth can be thought of as the Organization-Level perspective: the complexity that results from the amount of different tech stack of the different applications / services that the whole organization owns.
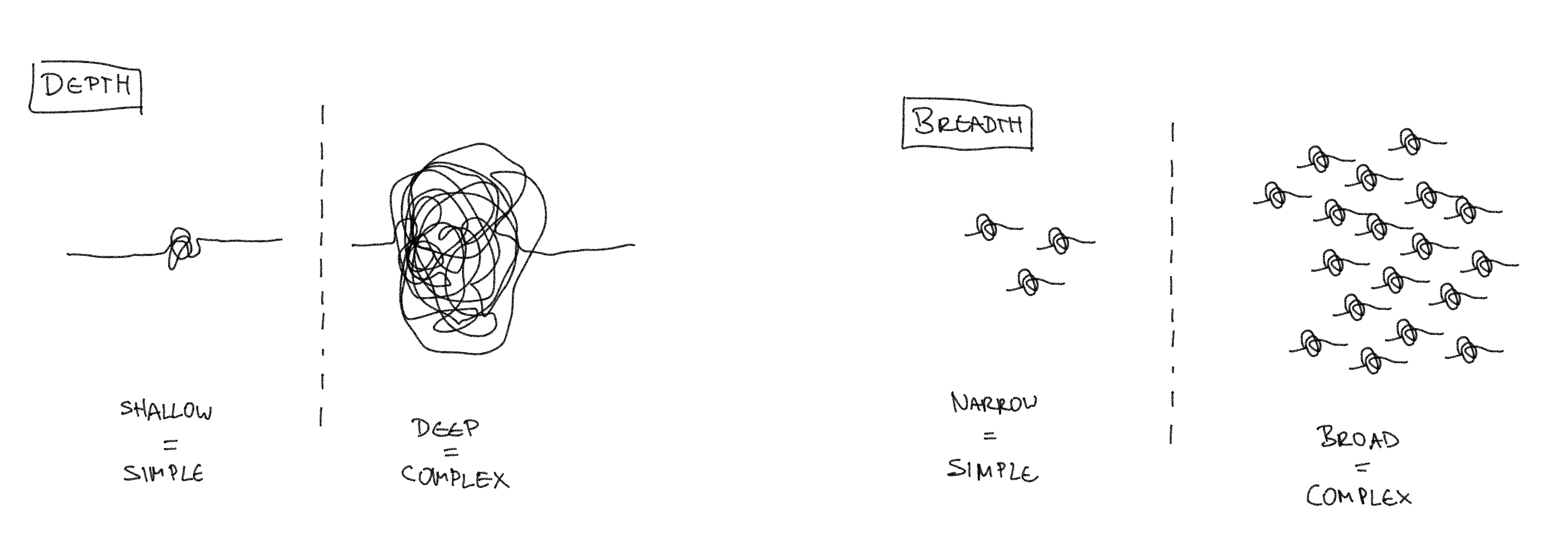
With that out of the way, what does end-to-end responsibility at scale mean then? It refers to the challenge your owner teams are facing when they have to handle either a large amount of applications or very complicated applications – or usually both. This challenge relates to the complexity they have to deal with. The total complexity that owners are grappling with results from the earlier mentioned Depth and the Breadths. Think of it like an “area of complexity”, that is the product of multiplying Depths and Breadth. As long as that area is big, it doesn’t matter whether it comes from a wide Breadths or a deep Depths (or both). With scale complexity grows. With rising complexity the challenge grows.
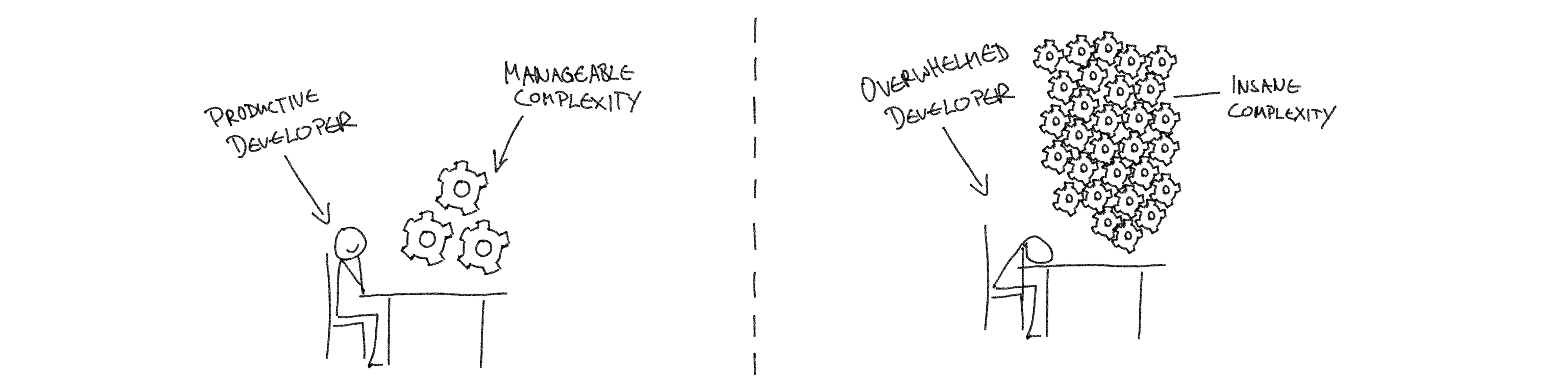
So what exactly is the problem with high complexity for end-to-end responsibility at scale? What it comes down to is cognitive load. Complexity is a measure that describes how many parts and how many connections between those parts exist in a system. More parts with more connections means more complex. When you think of a system that you see in the real world (or the virtual world) then your mind creates a mental model of that system in your head. This mental model allows you then to reason about the system: “here we can add this feature we talked about” or “this is likely the cause of the issue we are seeing”.
Let’s make this more practical. Imagine you are the current engineer on-call of a team that owns an application. Alarms go off, some metrics turn red, you have to find out what went wrong and then fix it. Let’s say your application uses five different infrastructure components. Each of them could have failed and caused the issue. With such a small amount and you easily understand how they interact and relate to each other. It takes you only a few minutes and a couple of log lines to narrow down the issue, identify the faulty component and perform a fix. Nicely done! Now, how do you reckon the story would have played out if there would have been fifty different infrastructure components involved? What about five hundred? What about magnitudes more? I think you can see the problem. The more moving parts are involved, the harder it gets to make sense of them all. We humans are simply limited in that regard. An end-to-end responsible team must be able to model their whole product, including all related processes and components that they own. In summary that means: end-to-end responsible teams are staffed with humans that can get overwhelmed by exceeding complexity, at which point any thought of responsibility goes right out of the window.
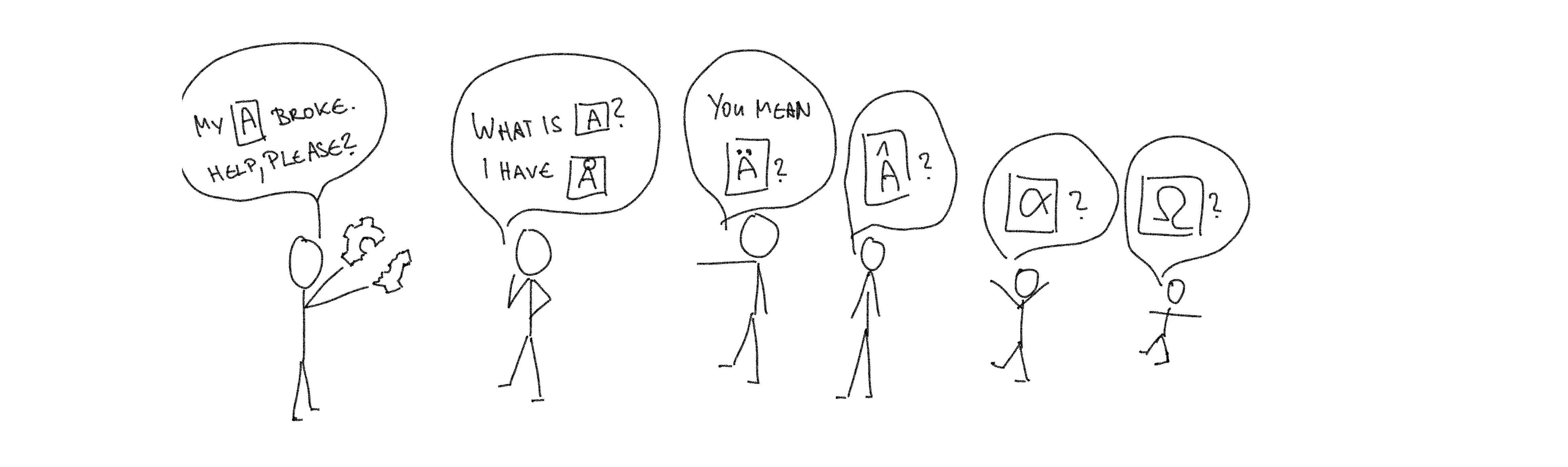
Look at it also from the organizational perspective: Imagine you have two teams that all are end-to-end responsible for their applications. They all take this very seriously and have designed ideally fitting tech stacks for their individual needs. As both team’s applications are different and both teams are solely responsible for the tech stack architecture, both tech stacks are different as well. Over time your organization grows. You now have fifty teams, with fifty different tech stacks. Oh wait no! That was last year. Now it’s a thousand teams and a thousand tech stacks. How easy is it for moving applications in between teams, given that they were designed and thought of individually? How easy is it to move people in between teams, given that they don’t know much about each other’s setup? And especially: Who can even begin to make sense of the combined tech stack of all your applications? How can you track security issues across that mess? How can you possibly start to think about efficient resource usage? There are no happy answers to these questions. If the complexity of the whole organization is not fathomable anymore, even at a high level, then it becomes impossible to direct it. Without direction your organization is little more than a headless chicken that runs in circles until it dies. That means: too many end-to-end responsible teams that are not aligned add more trouble than they add value.
All of the above are the problems that result from end-to-end responsibility adhering teams at scale. Well, the problems arise if your approach is naive and if you apply the model almost blindly on a team level. Of course: you should not.
How does End-to-End Responsibility work at Scale?
If exploding complexity is at the heart of the problem of scaling end-to-end responsibility then surely the solution is to reduce it? Right! Easily said. How do you do that exactly?
Consider again the team perspective. Above I argued that complexity results from the amount of moving parts that individual products (applications) are made of. More parts make equals more complex. With that the solution seems trivial: less parts make it less complex? Alright, I buy that for the moment. Let’s say your goal is simplification.
We also need to look again at the organizational standpoint. Complexity here emerges from the sheer amount of different architectures. Following again the obvious pathway: reduce the amount of architectures. Your goal is standardization.
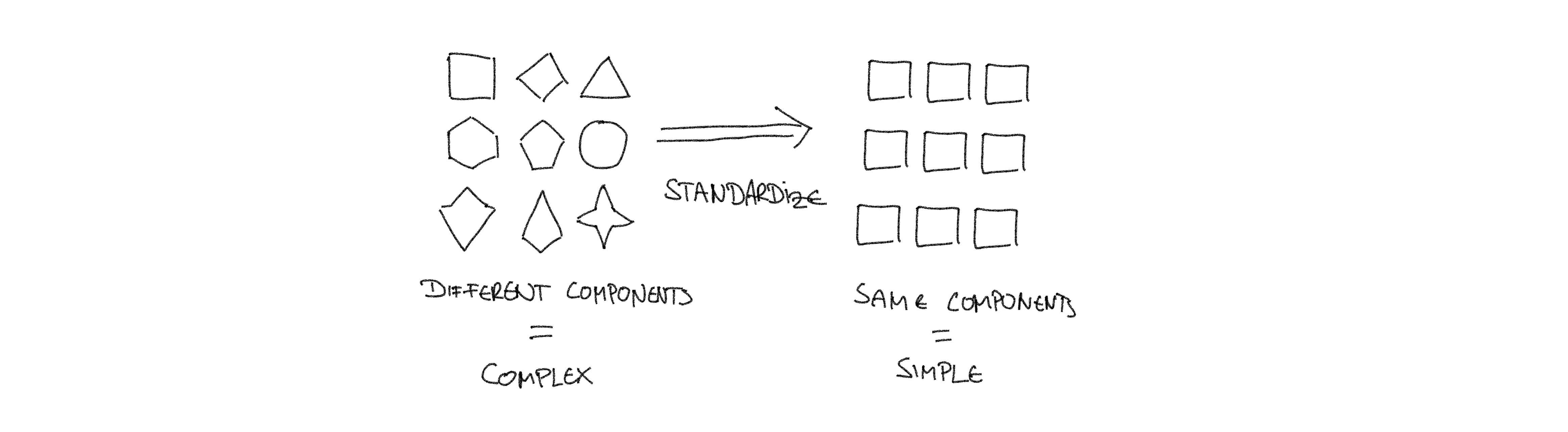
So what you are looking for is something that helps you to standardize your tech stack throughout the organization while simplifying the components that owners engage with. A tall order, for sure, but don’t fret there is an answer. You may have guessed it by now: platform engineering.
Right, that may need some more elaboration. There is two parts to that:
- How does platform engineering standardize and simplify your tech stack?
- How can end-to-end responsible teams work upon platforms?
The first part is easy to explain. Let’s start with the obvious: Platform engineers build platforms. Now, what are platforms? Platforms are systems that reduce the complexity of underlying systems. I wrote a whole article about that, please find it here. In summary: Using many (infrastructure) components directly means that you need to engage with the interface of each individual component. Each component adds some amount of complexity. The sum of the complexity of all the components is then the complexity that is surfaced to you, that you have to understand and handle in order to manage the components. A platform hides away the individual components and their complexity. It instead exposes a much smaller interface to you. Meaning you need to understand way less in order to manage the same resources. This is only possible at by giving up fine-grained control over those resources. This is a good thing, because it frees your resources for doing things that generate value instead. Another consequence is of course that with less choice comes less variety. Standardization. In essence, platforms refine the vast amount of complicated components into a small amount of simple components. By that, platforms are the foundation that both simplifies and standardizes your tech stack.
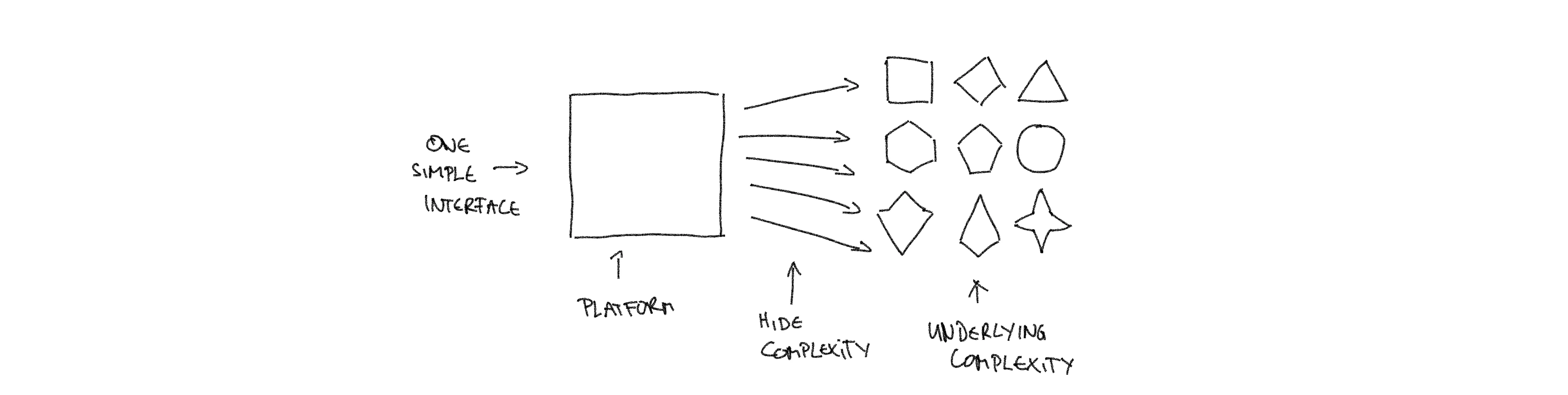
Now to the second part: how end-to-end responsible teams can work with platforms. Let’s have a look at a practical example in which your owner teams work directly with cloud infrastructure resources. Let’s say they are using AWS and some CDK flavor to manage their infrastructure as code. Providers like AWS have a huge range of products by now. Many of those build upon other products they have. For example, you could buy compute resources in the form of virtual servers and then install and maintain a container orchestrator like Kubernetes on it. Or you could directly buy a managed Kubernetes from AWS. Or you could buy a managed orchestration that hides away how it is implemented. That means: if you work directly with a cloud provider like AWS, then you are already building upon a platform. Actually upon multiple platforms that just pretend to be a single one (don’t get me started). The only difference between an AWS provided platform (building cloud infrastructure) and an in-house platform (building on cloud infrastructure) is that providers like AWS have to generalize their solutions to fit a large market, whereas in-house has the opportunity to optimize only for local use-cases. Hence the question of whether end-to-end responsibility adhering teams can work with platforms is entirely moot: they already do! Their responsibility is with the infrastructure components they own. The granularity of those components can differ (EC2 server vs high level orchestration abstraction), but that does not change anything about the end-to-end responsibility model. The more interesting question is whether an optimized and limited platform is better than a generalized and vast one. The answer is a resounding YES! Why? Using your own platform means that the components are optimized for your use-case. That means they are simpler. That means they much better decrease complexity than generalized components from a public provider.
However, building and running a platform is not for free. Hence one last question needs to be answered:
When does End-to-End responsibility require a Platform to work?
There are a couple of clear signals that tell you that you really, really need to reduce the complexity people are dealing with in order for them to take on the responsibility for their product. I outlined them with the wall that I described earlier (slowed down development, reliability problems, low employee retention, etc). However, if you are at that point, then you are already failing. If you don’t act, things will get worse – until they stop entirely of course. That makes it almost an easy decision. The more interesting question is how you can predict when you will need a platform way before that happens. If you are able to do that then you can formulate a sound strategy and follow it so you will never even start hemorrhaging employees, face customer backlash due to unreliable services or have to explain to investors why development stalled to a halt.
As I argued throughout this article: the decision of when a platform is required relates strongly to the complexity that individuals within end-to-end responsible teams are facing. The hard part is to get a clear measure of this complexity, so that you can gauge the current state or even begin to make predictions about the future development. To my knowledge there is no one magic metric that will give you a definite, actionable answer. However, from my observations of the years, I can give you at least a couple of proxy metrics that serve as early indicators. Which of them are best applicable depends strongly on the context of your particular situation. In general I would never rely on just one of them.
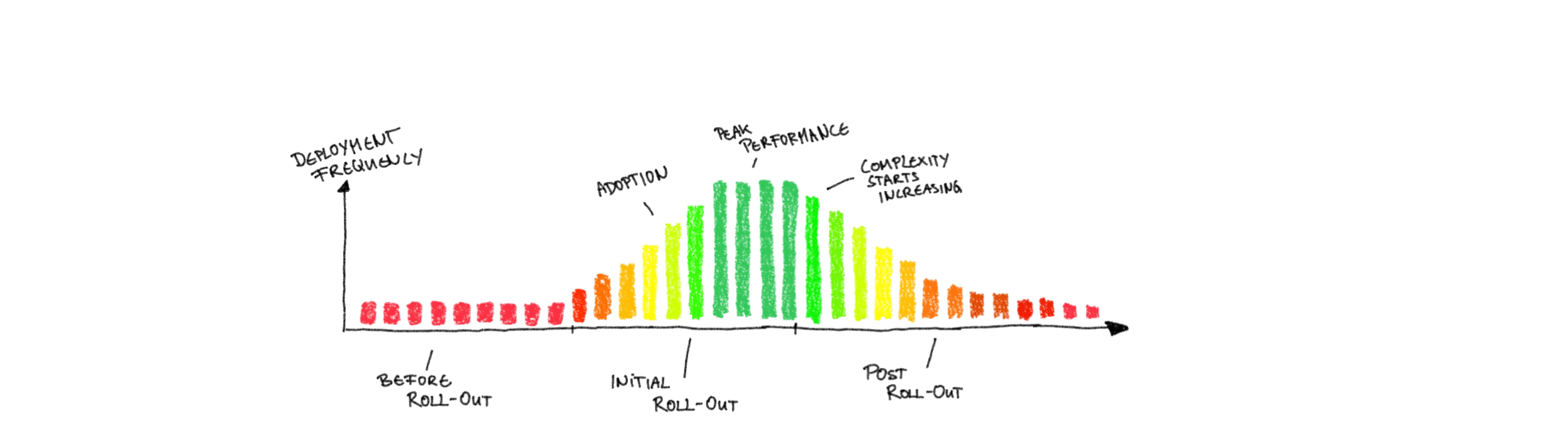
As end-to-end responsible teams own their infrastructure components, an increased complexity translates into more time that needs to be invested to manage them. Setting up monitoring for more components with more intricate relations can quickly become exponentially harder. Rolling-out changes into systems with more moving parts can add magnitudes of stress and failure potential. As a result, Deployment Frequency will decrease with increased infrastructure complexity, because each individual deployment is harder and more time consuming. And also because individuals will increasingly eschew to go through the hassle and the perils of roll-out.
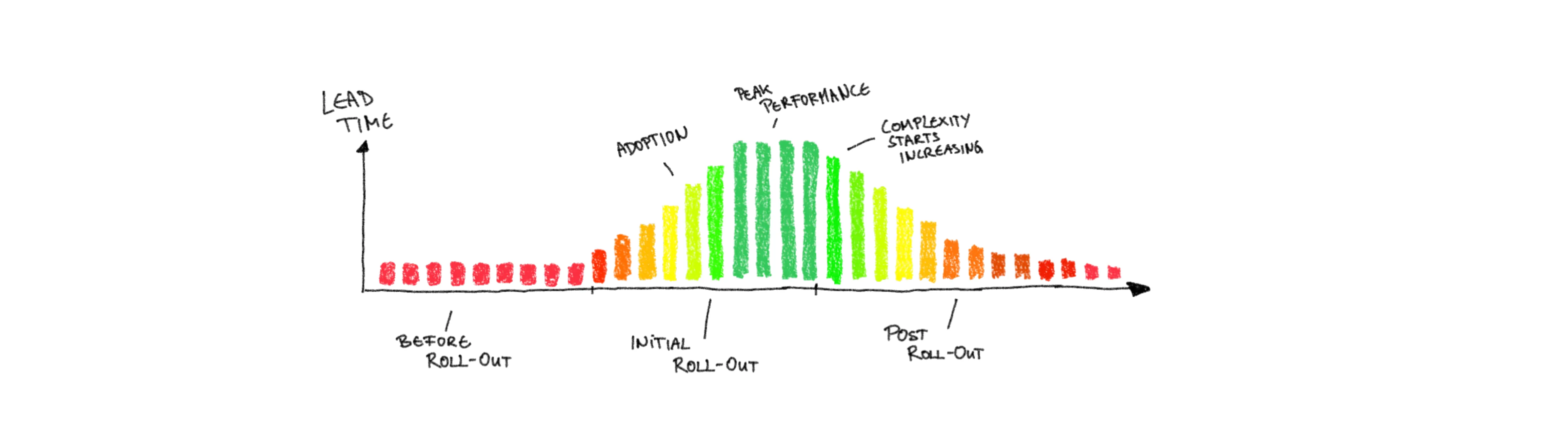
Not only that, but Lead Time for features to go from ideation to production will increase with increased infrastructure complexity, for the very same reasons of more time consuming deployments and more time invested into managing the infrastructure.
When it takes longer for any change to hit production, then it will take you also longer to roll-out fixes in incident scenarios. That means the Mean Time to Recovery (MTTR) will increase with increased infrastructure complexity. This one is a doozy, because, unless you are really seeing significant increases in a short time, it will sneak up on you. One or two required recoveries within a few months’ time rarely ring the alarm bells loud enough.
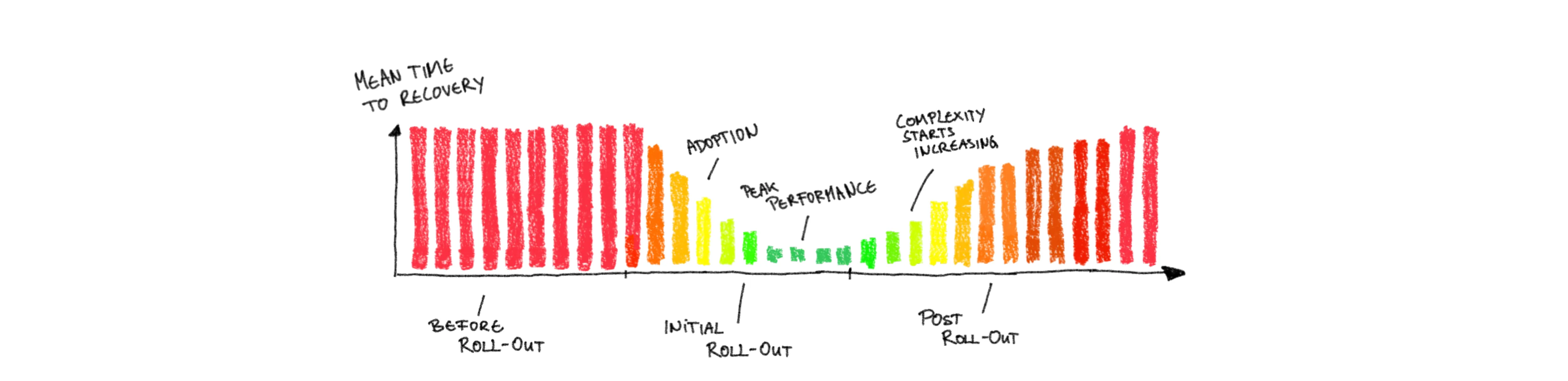
Recovery is, of course, following incidents that have already happened. Before it gets to that point you should see alarms that do not result in incidents either because they are caught early enough to counter them, or because they subside on their own. Hence the metrics that you should watch like a hawk is the Amount of Oncall Alarms that will increase with increased infrastructure complexity, because more complicated systems are easier to break, easier to misunderstand and harder to fix even if understood.
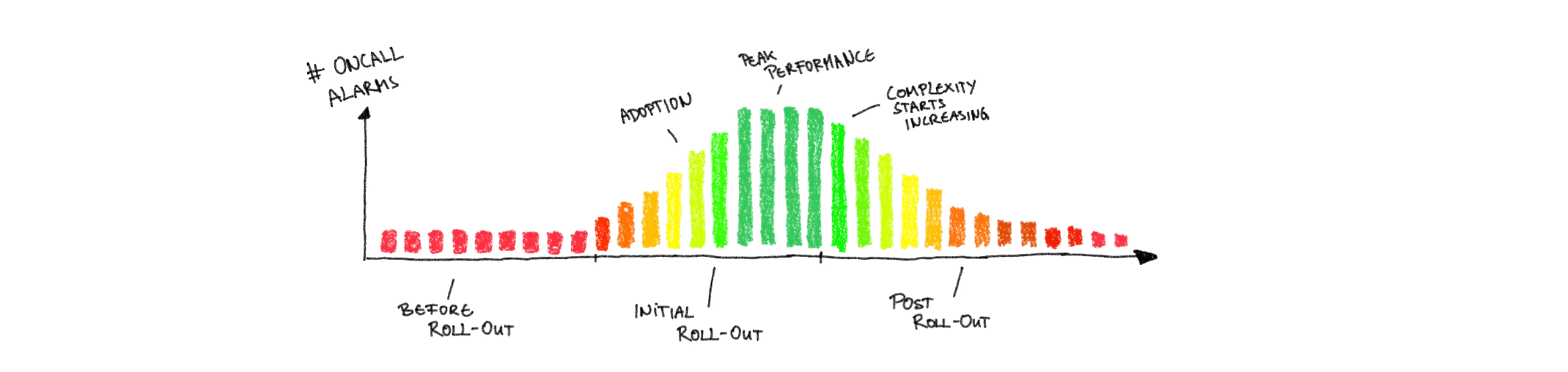
Underlying this alarm increase is, more often than not, human error, caused by cognitive overload that stems from the inability to model the whole complex system in your mind. Without that big picture it is rather easy to make decisions that do not account for the interplay of all components. A proxy for that is the relation between incidents and roll-out of changes, which is captured in the Change Failure Rate that will increase with increased infrastructure complexity.
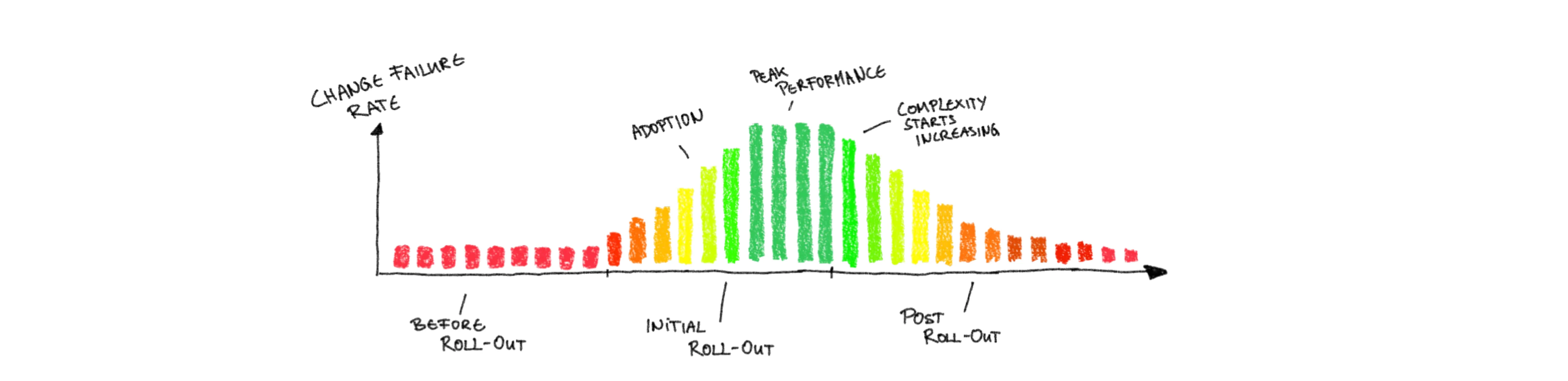
If you are able to track with some precision where the work of your teams is spent, then you will of course see that Time Spend On Infrastructure Management increases with increased infrastructure complexity. While some seasonal, temporary cost increase is fine and even continuous expenditure to keep technical debt at bay is expected, at a certain point it becomes counter to the idea of end-to-end responsible teams. After all, they were founded to speed up the time from ideation to production and increase productivity, not keep more people busy with infrastructure concerns.
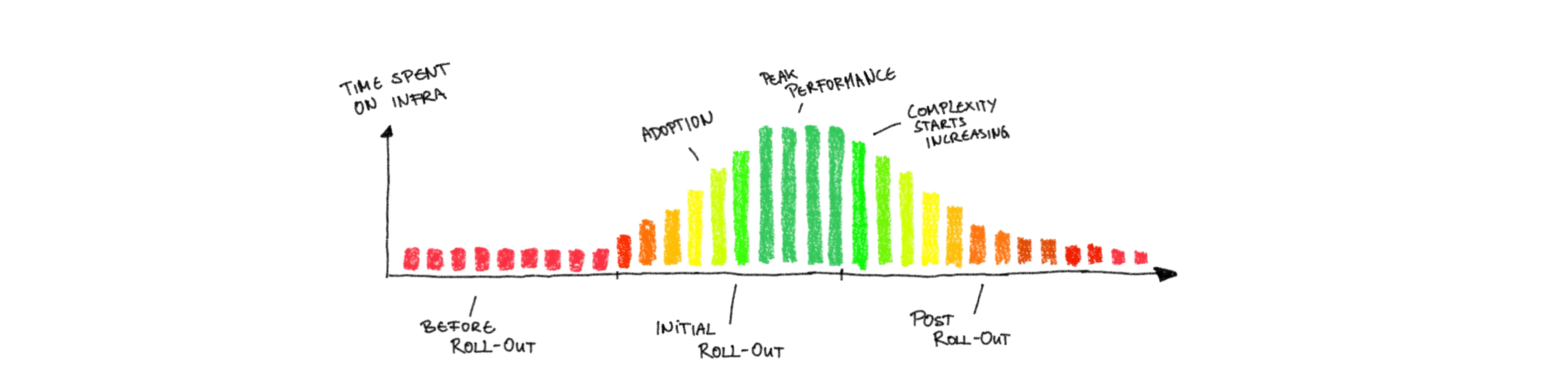
Last, but certainly not least, is the obvious: ask the very people that are working in the teams. You need, of course, a comparable metric that you track over a long enough time. Adding questions about time spent in infrastructure in your regular pulse surveys is a good start. Generally Employee Satisfaction and Engagement will decrease with increased infrastructure complexity, assuming that the majority of end-to-end responsible teams are focused on delivering business value and get frustrated if they are instead bogged down in battling with infrastructure.
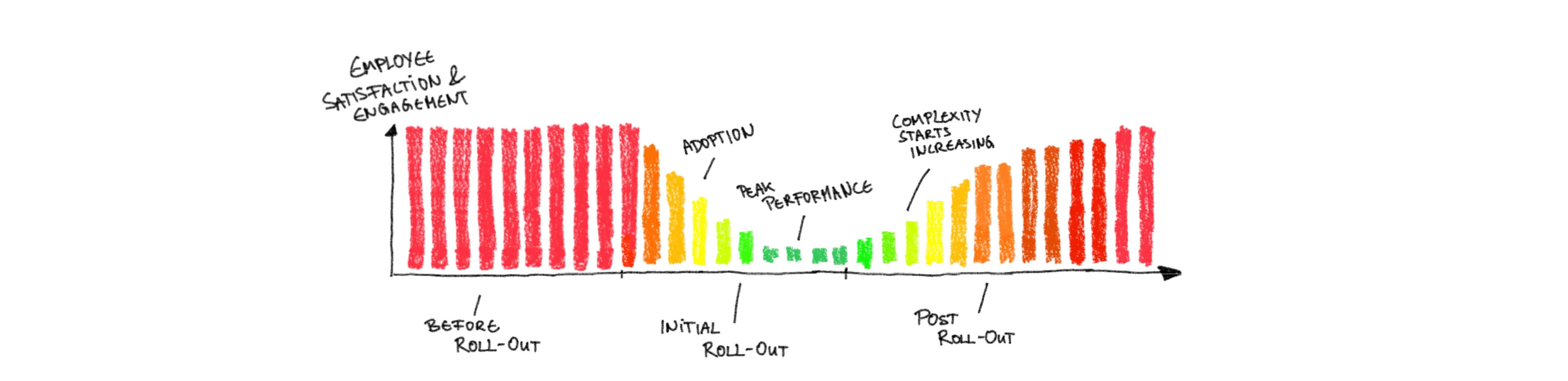
Again, you need more than a single metric measured in a single team to get a reliable signal. However, in conjunction with each other – of at least a subset of the metrics – you will certainly see a clear trend emerging way before you are suffering serious consequences. Keep your eyes open and be ready to simplify and standardize the complexity that development is facing. Platforms are an incredibly helpful tool here, if they are widely and wisely deployed.
Conclusion
The end-to-end responsibility model works at any scale – given that you provide the right environment for it to flourish. That means you have to perpetually rein in the complexity that members of end-to-end responsible teams have to engage with. You also need to make sure that no chaos ensues from a too large variety of solutions that result from too many teams creating optimal solutions for only their own domain. Platforms are a great way to address both concerns.
Platforms are also not the end of the story. Well, at least a single platform is not. As you keep growing, so does the complexity of your infrastructure. Over time you will see higher level patterns emerge: platforms upon platforms upon platforms. It’s a greater journey ahead!
As for my next article: I am pleasantly surprised to find myself deeply immersed and thoroughly enjoying an adjacent topic to platform engineering: developer experience. My interest, coming from the platform engineering side, has narrowed down over the years and I became more and more involved in the very intersection of development and platforming. When the rubber hits the road, so to speak. I am now actively exploring topics such as knowledge sharing and general developer tooling, which are other equally interesting problems that you face when engaging in development at scale. Stay tuned, more to come!


